
A Primer on Memory Consistency and Cache Coherence
介绍 Cache 一致性和内存一致性的书,全英文比较难读,以记录关键段落为主。
I. Introduction to Consistency and Coherence
Consistency definitions provide rules about loads and
stores (or memory reads and writes) and how they act upon memory.
Consistency 的定义提供了关于 load/store 的规则和在内存上的行为表现。
The microarchitecture-the hardware design of the processor cores and the shared memory system-must enforce the desired consistency model
微结构,处理器的硬件设计,必须强制需要的一致性模型。
在有 cache 功能的共享内存系统中可能存在潜在的乱序(eg.顺序读取 a 和 b,但是 b 在 cache 中 a 在内存中,b 会先返回)。
Coherence 尝试使得 cache 一致性在单核系统中对程序不可见,首先介绍 Cache Coherence,因为这个对 Memory Consistency 很重要。
Consistency models define correct shared memory behavior in terms of loads and stores (memory reads and writes), without reference to caches or coherence.
内存一致性模型定义了 load/store 下的正确的共享内存行为,而不用参考 cache 和 cache 一致性。
Access to stale data (incoherence) is prevented using a coherence protocol, which is a set of rules implemented by the distributed set of actors within a system. Essentially, all of the variants make one processor’s write visible to the other processors by propagating the write to all caches, i.e., keeping the calendar in sync with the online schedule. But protocols differ in when and how the syncing happens.
cache 一致性协议访问禁止访问不新鲜的数据,一致性协议是系统中各种行为的分布式集合。所有类型的一致性协议都是都让一个处理器的写对其他处理器可见,通过持续传播写到所有的 cache 的方式。但是在同步的时间和方式上不一样。
最后介绍了每章的主要内容,然后提出几个问题。
II. Coherence Basics
Baseline System Model
基本系统模型,包括一个多核处理器和主存,如下图所示。
LLC 指 Last Level Cache,最后一级 Cache,被所有处理器核共享访问。
The LLC also serves as an on-chip memory controller.
LLC 也作为内存控制器,基本模型分析时暂时忽略一些特性。
- instruction caches
- multiple-level caches
- caches shared among multiple cores
- virtually addressed caches
- TLBs
- coherent direct memory access(DMA)
The Problem: How Incoherence Could Possibly Occur
一种非一致性发生的情况,两个处理器执行时一边修改了数据但是另一边没有读到,因为 cache 里已经有数据了不会从内存中重新刷新。
The Cache Coherence Interface
一致性协议必须保证写操作后需要对其它处理器可见,下面介绍两种协议实现方式
We classify these protocols into two categories based on the nature of their coherence interfaces—specifically, based on whether there is a clean separation of coherence from the consistency model or whether they are indivisible.
- Consistency-agnostic coherence
不管内存一致性,写的时候其他全部可见,等价于原子内存系统(没有 cache),直接把 cache 抽象成统一的一个 memory - Consistency-directed coherence
写在返回的时候不被其他处理器看到,但是顺序要满足内存一致性,支持了通用 GPU 这种大吞吐应用
(Consistency-Agnostic) Coherence Invariants
We define coherence through the single-writer–multiple-reader (SWMR) invariant.
通过 SWMR(单写多读)定义 Cache 一致性。
对于给定的内存区域,同一时间只有一个处理器读/写或者多个处理器读。
除 SWMR 之外还要保证数据正确性,不能 CORE2 和 CORE5 同时读取却读到了不一样的数据。
一个阶段的数据和这个位置在上一个读写阶段结束时的数据相同。
一致性的粒度通常和 cache 块一致,对于每个块有一个写或者多个读
如果一个核想读一块地址,发信息给其他核以保存当前地址数据,并且确保其他核没有拷贝
Sequential consistency (SC), a memory consistency model that we discuss in great depth in Chapter 3, specifies that the system must appear to execute all threads’ loads and stores to all memory locations in a total order that respects the program order of each thread.
Sequential Consistency (SC) 在下章具体讲解,指明为了执行所有线程的 load/store 对于所有的内存位置能够保证每个线程的程序顺序的全局顺序。
A definition of coherence that is analogous to the definition of SC is that a coherent system must appear to execute all threads’ loads and stores to a single memory location in a total order that respects the program order of each thread.
类似 SC 的定义,coherent 系统中对于每一个内存位置的操作都必须遵守每个线程的程序顺序。
coherence 对于每个内存位置,consistency 是对所有的内存位置
III. Memory Consistency Motivation and Sequential Consistency
深入内存一致性模型,内存模型定义了共享内存系统的行为。
正确的模型能让程序员知道预期结果、让处理器设计者知道提供什么。
多核共享内存系统中乱序出现的一些情况。
不同的地址不同的操作才能乱序,对同一个地址不能乱序。
- store-store 乱序:non-FIFO write buffer,单线程执行不受影响
- load-load 乱序:单核中乱序,但是结果被另一个核观测时出问题
- load-store 和 store-load 乱序:store-load 乱序可能因为 FIFO 的 write buffer 导致
共享内存总会出现不确定性,程序员无法完全控制。
内存一致性模型是有共享内存系统的多线程程序执行规范。
CONSISTENCY VS. COHERENCE:cache 一致性并没有定义内存行为,简单地为处理器核提供了内存系统的抽象。单独的 cache 一致性不能决定共享内存的行为,pipeline 也有很大影响,例如 pipline 乱序和分发内存操作到一致性协议,顺序与程序顺序不同,即使 cache 一致性正确执行,但是依然发生了乱序,共享内存系统就可能出错。总之,cache coherence 和 memory consistency 不同,内存一致性实现可以将 cache 一致性作为黑盒调用。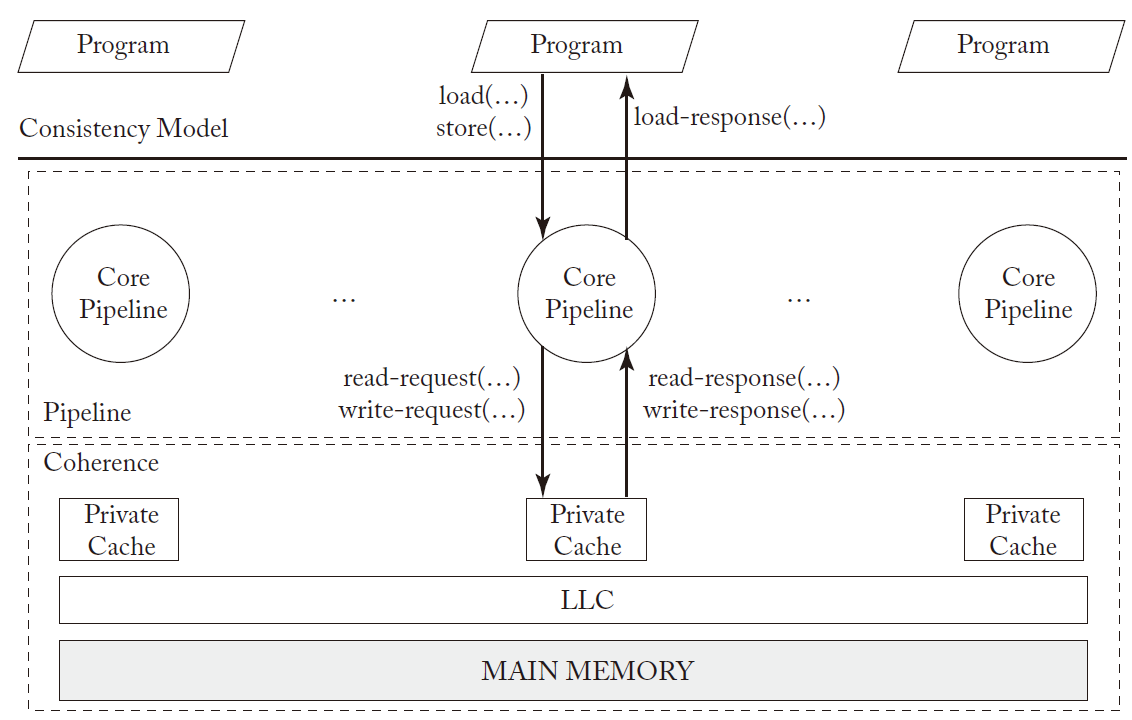
可以说最直观的内存一致性模型就是 SC(Sequential Consistency),这个首先由 Lamport 正式化,在“执行结果同严格按照程序顺序执行的程序结果相同”情况下,他将单核称作sequential。多核在类似情况下被称作sequentially consistent,“任何执行的结果都是一样的,如果所有核以一些连续顺序,同时每个单独处理器的操作出现在程序指明的序列中”,这个整体的顺序被称作 memory order。
在 SC 中,内存顺序尊重每个核的程序顺序,但是其他一致性模型可能使内存顺序不根据每个核的程序顺序。
“尊重”表示如果单个程序中操作数 op1 早于操作数 op2,则整体内存顺序上 op1 早于 op2。
具体 SC 特点在下图深入分析。
a-c 图描述了三种执行方式,图 d 是非 SC 执行,对于此时的输出没有办法创建一个这种结果的内存顺序。
图中情况的 SC 最多支持 6 中执行方式,不会出现第 7 种情况。
SC 执行需要遵守:
- 所有核插入到全局顺序种的 load/store 都必须按照原本的程序顺序
- 每个 load 得到的数据一定是上一次这个位置 store 的数据
原子 RMW 指令(eg. Test-and-Set)进一步限制了允许的执行。
SC的实现要求严格,仅仅允许SC执行,严格地说,为了SC实现的安全。具体地说,一个store对于另一个同一个位置持续反复的load必须最终可见,这个属性被称作最终写传播。更普遍地说,避免饥饿和公平性是很重要的,但是这些问题暂时不考虑。
参考链接

- 本文作者: Zheng Yuchen
- 本文链接: https://zycccccc.top/2022/01/02/读书笔记/A Primer on Memory Consistency and Cache Coherence/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!